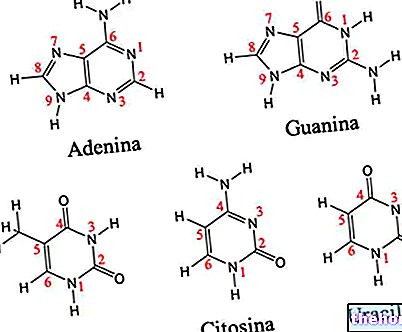
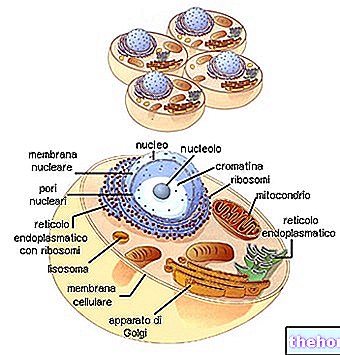
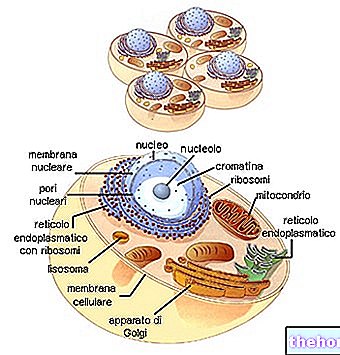
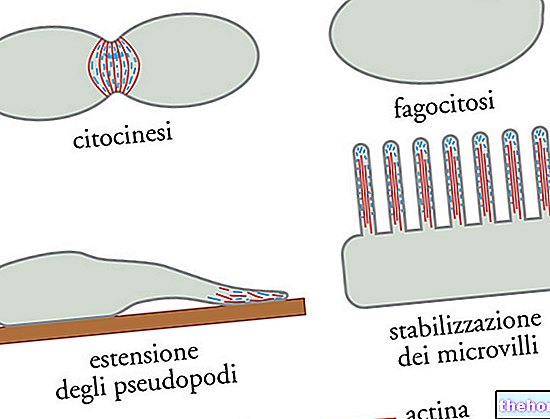
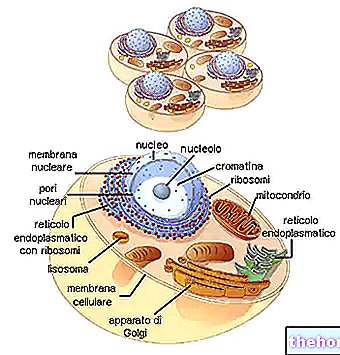
Para que exista una correspondencia entre la información del polinucleótido y la del polipéptido, existe un código: el código genético.
Las características generales del código genético se pueden enumerar de la siguiente manera:
El código genético está formado por trillizos y carece de puntuación interna (Crick & Brenner,).
Fue "descifrado mediante el uso de" sistemas de traducción de células abiertas "(Nirenberg y Matthaei, 1961; Nirenberg y Leder, 1964; Korana, 1964).
Es muy degenerado (sinónimos).
La organización de la tabla de códigos no es accidental.
Trillizos "tonterías".
El código genético es "estándar", pero no "universal".
Mirando la tabla del código genético, hay que recordar que se refiere a la traducción de "ARNm a polipéptido, para lo cual las bases nucleotídicas involucradas son A, U, G, C. La biosíntesis de una cadena polipeptídica es la traducción de la secuencia de nucleótidos en la secuencia de aminoácidos.

Cada triplete de bases del ARNm, llamado codón, tiene la primera base en la columna de la izquierda, la segunda en la fila superior, la tercera en la columna de la derecha. Tomemos por ejemplo el triptófano (es decir, Try) y vemos que el codón correspondiente será ser, en orden, UGG. De hecho, la primera base, U, incluye toda la fila de cajas en la parte superior; en este, G identifica el cuadro más a la derecha y la cuarta línea del cuadro en sí, donde encontramos escrito Try. Del mismo modo, para sintetizar el tetrapéptido Leucina-Alanina-Arginina-Serína (símbolos Leu-Ala-Arg-Ser) podemos encontrar los codones UUA-AUC-AGA-UCA en el código.

En este punto, sin embargo, debe tenerse en cuenta que todos los aminoácidos de nuestro tetrapéptido están codificados (a diferencia del triptófano) por más de un codón. No es casualidad que en el ejemplo recién informado hayamos elegido los codones indicados, podríamos haber codificado el mismo tripéptido con una secuencia de ARNm diferente, como CUC-GCC-CGG-UCC.
Inicialmente, al hecho de que un solo aminoácido correspondiera a más de un triplete se le dio un significado de aleatoriedad, también expresado en la elección del término de degeneración del código, utilizado para definir el fenómeno de sinonimia. Por otro lado, algunos datos sugieren que la disponibilidad de sinónimos referidos a una estabilidad diferente de la información genética no es en absoluto accidental. Esto parece confirmarse también por el hallazgo de un valor diferente de la relación A + T / G + C en las diferentes etapas de la evolución. Por ejemplo, en los procariotas, donde la necesidad de variabilidad no se satisface con las reglas del mendelismo y el neomendilismo, la relación A + T / G + C tiende a aumentar. La consiguiente menor estabilidad, ante mutaciones, proporciona una mayor oportunidades de variabilidad aleatorias de la mutación genética.
En eucariotas, en particular en células multicelulares, en las que es necesario que las células de un solo organismo mantengan el mismo patrimonio hereditario, la relación A + T / G + C en el ADN tiende a disminuir, disminuyendo la posibilidad de mutaciones genéticas somáticas. .
La existencia de codones sinónimos en el código genético plantea el problema, ya mencionado, de la multiplicidad o no de anticodones en el RNAt.
Es cierto que hay al menos un ARNt para cada aminoácido, pero no es igualmente seguro si un solo ARNt puede unirse a un solo codón, o puede reconocer sinónimos indiferentemente (especialmente cuando estos difieren solo para la tercera base).
Podemos concluir que hay en promedio tres codones sinónimos para cada aminoácido, mientras que los anticodón son al menos uno y no más de tres.
Recordando que los genes están pensados como tramos únicos de secuencias de polinucleótidos de ADN muy largas, está claro que el principio y el final del gen único deben estar necesariamente contenidos en la memoria.
BIOSÍNTESIS DE PROTEÍNAS
En diferentes partes del ADN se produce la apertura de la doble cadena y la síntesis de los diferentes tipos de ARN.
Durante el paso de carga, el RNAt se une a los aminoácidos (previamente activados por el ATP y por la enzima específica). La "maquinaria" biosintética es incapaz de "corregir" los ARNt cargados incorrectamente.
El ARNr luego se divide en dos subunidades y, al unirse a las proteínas ribosómicas, da lugar al ensamblaje de los ribosomas.
El ARNm, al pasar por el citoplasma, se une a los ribosomas, formando el polisoma. Cada ribosoma, que fluye sobre el mensajero, hospeda gradualmente el ARNt complementario a los codones relativos, tomando los aminoácidos y uniéndolos a la cadena polipeptídica en formación.
El ARNt relativamente estable vuelve a entrar en la circulación. Los ribosomas también se utilizan nuevamente, liberando el polipéptido ya ensamblado.
El mensajero, menos estable porque es todo monocatenario, es escindido (por la ribonucleasa) en los ribonucleótidos constituyentes.
El ciclo continúa así, sintetizando uno tras otro los polipéptidos en los ARN mensajeros suministrados por la transcripción.